



The 2024 Procedural Content Generation Workshop Round-up | AI and Games Newsletter 03/07/24
Catching up on procedural generation research!

The AI and Games Newsletter brings concise and informative discussion on artificial intelligence for video games each and every week. Plus summarising all of our content released across various channels, from YouTube videos to episodes of our podcast ‘Branching Factor’ and in-person events.
You can subscribe to and support AI and Games right here on Substack, with weekly editions appearing in your inbox. The newsletter is also shared with our audience on LinkedIn. If you’d like to sponsor this newsletter, and get your name in front of over 3000 weekly readers, please visit our sponsorship enquiries page.
Hello all,
here and welcome back to the AI and Games newsletter, I’m back at my desk and still largely recovering from the past two weeks of work and travel at both the AI and Games Summer School and Schloss Dagstuhl’s seminar on Computational Creativity for Games.
Right now I’m busy preparing for my trip to Develop: Brighton, but for this week we’re taking a little sojourn into academic research in AI and related technologies for games, and this time around I had a little help in bringing this to you!
But before we get into this weeks announcements, a heads up that I’m taking a wee break!

A Summer Hiatus
The AI and Games newsletter will be taking a short break until the end of July. As you can imagine, writing a weekly newsletter can be a challenge, and even more so when you’re busy with a lot of goings on in the field. So understandably, I deserve a wee break!
After Develop: Brighton next week I’m going on a short vacation. I figured that rather than rush to find alternate material to keep you all entertained in the downtime, it would be best to press pause, and then return with a bunch of talking points both from my visits to the likes of Schloss Dagstuhl and Develop, but also some of the broader goings on around the industry.
This also means that our monthly video updates and Branching Factor will be paused for a few weeks. The work in producing both video content as well as the podcast is an ongoing one, and while I’m taking a break, we have a stack of content lined up in the coming months. My recent episode on the AI of Dark Souls is but one of several topics lined up where we revisit some classic games. Plus we also have some very exciting work on more contemporary titles in the pipeline!

But before I log off, I want to take a moment to thank everyone for their tremendous enthusiasm for my work here on the AI and Games Newsletter. I launched this project at the start of 2024, without any real idea of what kind of traction it might gain. I’ve happy to say that numbers have continued to climb, and already I’ve seen a significant increase in subscribers both here on Substack and on LinkedIn as well. Plus I have had the pleasure of meeting several of my readers at events in recent weeks and have some great conversations off the back of it.
I’m excited to continue to provide a small window into this weird and cumbersome world of AI for games, and look forward to getting back into the swing of things soon!
Quick Announcements
Next week I’m at Develop: Brighton and looking to arrange a meeting to discuss life, the universe, and everything - or more importantly potential collaborations and sponsoring my upcoming Goal State project - can find me on the Meet to Match site, as well as on my Calendly page.
This month’s Sponsor Newsletter will go live later this week. This is for supporters of AI and Games across YouTube, Patreon and Substack. In which I will be filling in readers on what to expect from AI and Games for the rest of 2024.
The PCG Workshop Round-up
Since I started the AI and Games newsletter earlier this year, one aspiration I’ve had is to find ways for my audience to better connect with the rich and interesting work that emerges in academic communities. Regular readers will know I come from the world of academic research in AI for games: I earned my PhD on the topic way back in 2010 - long before ‘AI for games’ was considered interesting - and subsequently published numerous papers in various aspects of AI intersecting with games. As such, part of me always has an eye on what emerges from academic research conferences, with a mixture of interesting, ground-breaking, eclectic and on occasion just outright bizarre ideas.

But sadly I seldom get to attend these events anymore, given they’re often expensive to attend and, when considered in the context of my day-to-day work, I can’t really justify them nowadays.
And so for this weeks newsletter we have something rather special, our first ever guest author on AI and Games! Please give a warm welcome to Victoire Hervé, a PhD student at the University of Hertfordshire in the UK who was kind enough to summarise the research shown at the Procedural Content Generation (PCG) Workshop at the Foundation of Digital Games (FDG) conference which ran at the Worcester Polytechnic Institute in the US back in May.
The FDG conference caters to both technical and humanities research in game design and development, and has been the home of the PCG workshop since its inception. The organisation of such events (both the conference and the workshop) passes hands over the years. In fact, I was one of the organisers of the FDG workshop way back in 2017 having published there several years in a row.
Victoire is a perfect candidate for delivering this summary, given they are one of the organisers of this years workshop. Thus providing a particular lens through which to critique the work that appears at the event.
And with my introduction out of the way, Victoire, the floor is yours!

PCG @ FDG 2024
Hi I am Victoire HERVÉ, a former software engineer in the video game industry (Crytek, Spiders Games, …), and now a PhD student at the University of Hertfordshire (UK). My main interest of research is Procedural Content Generation (PCG), in other words the creation of video game content (graphics assets, storylets, gameplay elements, …) through algorithms. I focus in particular on generating unique and meaningful content, and my approach is to look at player’s experience. In addition, I also co-organise the Generative Design in Minecraft Competition (GDMC), which is a very cool competition and if you own Minecraft, I encourage you to check out what our participants have been doing through the last years.
[Tommy here: if you’re curious about the GDMC competition, I made a video about it on the AI and Games YouTube channel back in 2019]
[Sorry Victoire, please continue…]
Earlier this year, I was asked to co-organise the PCG workshop at the Foundations of Digital Games conference, and I am here today to tell you a bit about the research papers that were presented there!
I am always excited about the PCG Workshop. As a research event, it lands right in the right spots between novel (sometimes crazy) ideas, and scientific strictness. This year however, I was a bit afraid of the field of Generative AI as a whole.
As an organiser, I was expecting that most of the submissions would be based on Large Language Models (LLMs like GPT) and Diffusion models (like DALL-E). Not that I am fundamentally against them, but I was concerned that our track might be filled with paper named "Text to [insert game asset's type]". It turns out that not only I was proven wrong, but also this year's workshop was filled with insightful and exciting research.

We ended up with only one LLM based paper, but in my view, a very valuable one. 'Prompt Wrangling: On Replication and Generalization in Large Language Models for PCG Levels' is a paper rooted in the 'ChatGPT4PCG' competition, in which participants submit not code, but a GPT prompt in charge of producing a script for generating Angry Bird's levels. The scoring of the competition was fully automatized, therefore the authors decided to reproduce the competition, with the same entries. The aim was to check if they could reproduce the same result, but also generalise them, by running the competition in new settings. The authors showed that generalisation was still an open problem, with few success to get similar rankings in any different settings. They also failed to reproduce the results of the original competition. One of the reasons they invoke is the close-source nature of the used model, with the impossibility to understand how it evolved since the competition and what changes led to the ranking difference. These results are very insightful and raise questions that we should all take into account when relying on LLMs for PCG, especially when using closed source technologies. I personally welcome such reflections on new and popular generating methods.
Speaking of trending generating methods, we can't have a proper PCG Workshop without any Wave Function Collapse (or WFC, a modern and trendy algorithm for generating grid based content) paper! `Mixed-initiative generation of virtual worlds - a comparative study on the cognitive load of WFC and HSWFC` (HSWFC standing for `Hierarchical Semantic Wave Function Collapse`, an improvement of WFC providing more control over the generated content, introduced by the same authors as the paper currently being discussed.) is a continuation of previous work from the same research group, working on a mixed initiative WFC tool. The key contribution of the paper is not only the added features, but also that their design was driven by the reduction of the cognitive load they are providing. The cognitive load was evaluated using human testing, and overall the used method may be of interest for anyone working on tool design.
Another 'tooling' related paper is `Translating Between Game Generators with Asterism and Ceptre`, a short paper introducing an in-progress implementation of a conversion tool between 'Ceptre', a game description language that generate game on an abstract level (so abstract in fact that there is no graphical representation); and Asterism, a tool for generating game engines and therefore, you guessed it, graphical representation. The paper was mostly published to present the motivation, progress and struggles of the authors, but one can imagine what it would mean in terms of game generation if they were to succeed.
A final co-creativity tool, was presented `The Puzzle Forecast: Tutorial Analytics Predict Trial and Error`, which introduced 'TutoMate', a tool in charge of checking if a puzzle level successfully presents simple goal chains, without any fail state, effectively making the level a tutorial. I personally really liked that approach, which could be generalised to many games genres. This technique may be very valuable in the industry, in my own view, letting designers know if there is a loophole in their tutorial, and where exactly it is situated.
We also had several papers focusing on content evaluation, or in other words the automation of understanding generated content. I personally have a sweet spot for that, since this is my area of research, and let me tell you that the submitted papers were diverse, interesting and inspiring. `A Framework to Even-Out Racetrack Bias` for instance, focused on racetrack generation, and how to create an overall fair experience. The method developed by the authors is to look at each race segment individually, and to compare how different cars perform on each based on their properties (speed, weight, etc). The goal is not to even out the individual segment, but rather to distribute them in a way that creates a fair assembly. I personally salute the emphasis on the player's experience.
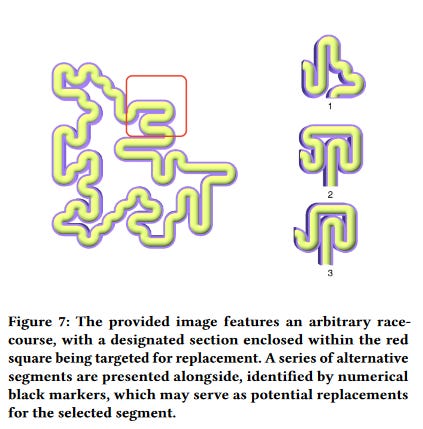
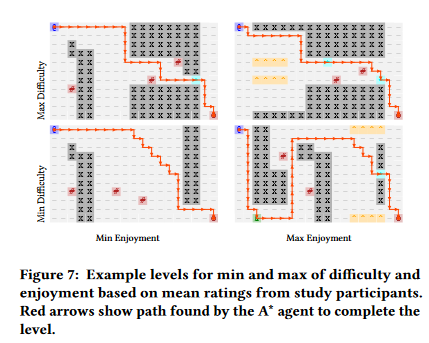
'Solution Path Heuristics for Predicting Difficulty and Enjoyment Ratings of Roguelike Level Segments' generates the A* path for a given Roguelike's level, and evaluate the path on different properties, such as the proximity with the enemies and bonuses. It is worth noting that this evaluation is made on each "state" of the game, as the player progresses along their path, taking into account the position of the enemies at each given point. The developed heuristics were tested against self reported player's enjoyment and difficulty rating. Unfortunately, no correlation was found between the predicted difficulty and player's enjoyment, but the approach remains interesting. Our field often focuses on making game levels 'playable', 'diverse', but as far as I know, there is not much research focusing that much on difficulty, which remains a key component of the player's experience. And bonus point for actually testing the experienced difficulty.
Still somehow related to content evaluation (or should I say content introspection?), we had two papers that were particularly novels. 'Towards Generating Surprising Content in 2D Platform Games' propose a practical implementation of the VCL (Violation of Expectation, Caught Off Guard, and Learning) model. Basically, it deceives expectations concerning the next generated output (in this case Super Mario levels), by modifying the values of certain parameters. The more the chosen metrics deviate with the previous level, the greater the reported surprise is. My favourite output of this paper is how different metrics lead to different impacts on the generated surprise, and it would be interesting to investigate further the behaviours of these. However, I have some concerns regarding the experiment. I can imagine how playing Mario with a different gravity can be surprising the first couple of times, but as soon as I perceive that it is another parameter in the level generation, it becomes predictable too. But let's admit it, it is still a super cool publication, and the future works sound promising.
'Experiments in Motivating Exploratory Agents' is a very experimental piece of work. It is essentially a modelisation of the player's exploring behaviour. The idea is to drop an agent within a set of 3D levels, both generated or recreated from existing video games, and observe if the model is actually able to identify uninspiring levels. While the authors acknowledge there is still room for improvement in their model, it is still an interesting first step, and their results are positive anyway. The aim of their research is to develop a model assisting the generation of interesting 3D levels, and I personally think it is a very good approach.
Finally, we had two very novel, almost bizarre papers.
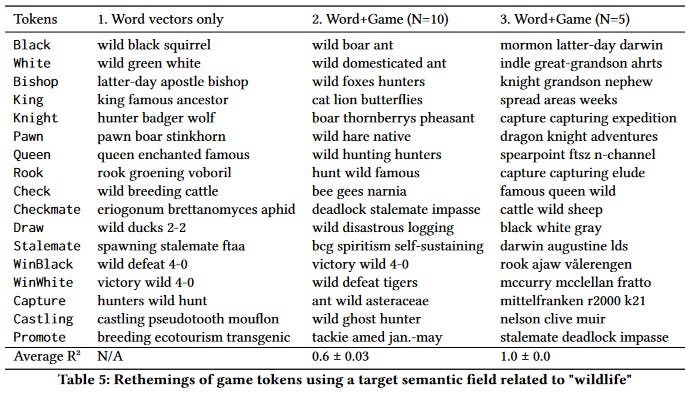
`“Hunt Takes Hare”: Theming Games Through Game-Word Vector Translation` is, on the surface, very simple. The concept is to translate the game's theme through vector translation. A single word/term is defined in the semantic space of the theme, and the retheming consists of translating this term in the same space, then reapplying the same vector translation to all the game's terms. For instance, if you were to relabel Chess to be themed with Wildlife, the same operation would turn the 'King' into a 'Lion' and the 'Pawn' into a 'Hare'. I am just scratching the surface here, but if you can grasp the potential of that technique, and are interested in getting deeper, the paper is well detailed and contains lots of examples.
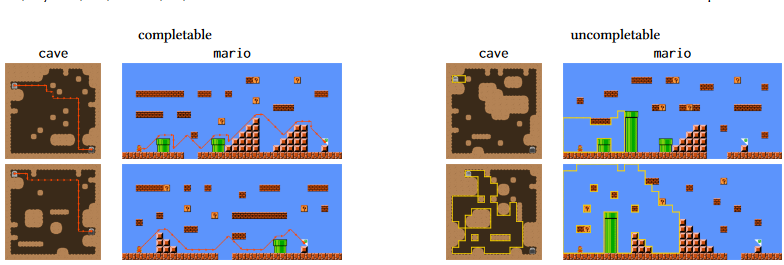
At last, the paper which can be considered the highlight of the workshop. Not that the others' papers were inferior, but the room loved that presentation, which was both funny and insightful. `Literally Unplayable: On Constraint-Based Generation of Uncompletable Levels` is a method for generating levels that... can't be complete. Does that sound silly? It is not! Because first of all, there are numerous ways to make a level non-finishable: you can block the player right from the start, close to the end, in the middle of the level, create doors without keys, introduce gaps that can't be crossed or puzzle without solutions, ... And just by reading that, you might also realise that all these blockers are not equals in terms of 'quality'. This is why the paper is not just about generating incomplete levels, but impossible levels that resemble the structure of completable ones. The authors name various use cases for their work, in particular the possibility of generating a dataset of faulty levels, but also to use their methods as a validation step for level generation; or even create levels that require the player to pull off a special move!
Even More PCG at FDG!
Other PCG related papers were presented during the main tracks of FDG, and I encourage you in particular to have a look at `DreamCraft: Text-Guided Generation of Functional 3D Environments in Minecraft`, a text-to-voxel generation algorithm (which won a best paper award); `On the Evaluation of Procedural Level Generation Systems`, a survey paper on how PCG is evaluated in research; and `Language-Driven Play: Large Language Models as Game-Playing Agents in Slay the Spire` a very cool use case for LLMs as a playing agent in charge of testing generated cards, even if they have no apparent use or synergies with existing ones. I just named a few, and I strongly encourage you to have a look at the entire Game Artificial Intelligence track.

On LLMs
As I stated earlier, I was at first a bit concerned about the over presence of LLMs during the conference, in particular in the PCG workshop. Turns out I was wrong, and also it feels like academia has reached a sort of a 'post LLMs boom' status. Not that the tech is now old fashioned or anything, but it feels like researcher are now more focused on analysing its performance and actual usefulness (with for instance `The Ink Splotch Effect: A Case Study on ChatGPT as a Co-Creative Game Designer` which was also presented during the Game AI track), or finding new use case for it that are not necessarily straightforward content generation (such as the `Slay the Spire` paper I mentioned earlier).
On Human evaluation and PCG
When I started my PhD, I was quickly confronted with the fact that our ways of evaluating generated content are often relying on metrics that poorly capture its quality, and sometimes even these metrics felt like they were made out of thin air. And again, more on that in the survey paper. I was positively surprised to see during the workshop that more and more researchers now test their generating techniques with actual people. Especially for co-creativity, I feel like the cognitive load approach was interesting, and it is a positive direction for the field of mixed initiative.
However, I am also afraid these results are a bit simple. It feels like most of the papers were relying on 'Mechanical Turk' by Amazon. While at first sight I had nothing against it, beside maybe a ethical concern, only one authors mentioned that their results might be biased, due to the fact that the testers were likely to be surprised to play a game in the middle of their other tasks, and also the demographic might not be comfortable with games in general. My main concern is now that we trade one evil for another, un-embody metrics based evaluation with a systematic default human testing approach that provides very limited results.
In Summary
Currently the field of Generative AI is going in every direction all at once. I feel like for a long time, our field of research was focusing on improving the quality of our outputs, but now that we are living in a world with Chat-GPT, Midjourney and others, the stakes are completely different. Sure we, as researchers but also gamers, have to digest these new tech. As someone that sat through all those presentations and listened to the talks, the questions, and the discussion, I have to say there is now always this underlying idea of “How does it compare to GPT?”. Is it applicable? Is it relevant? Would it work better?
This year’s workshop is an answer in itself to numerous questions: others generating methods are still relevant. Latest AI techs have their use cases and their flaws.
Creating unique and meaningful content might not be simply a question of quality and resolution.
It is nice to see the field slightly shifting recently. I am happy to see more and more interest in Human testing. I met with researchers using LLM to solve challenges I (we) have been struggling with. People are going in weird and funny directions, beyond the technologies. What if we could generate bad levels? What if we could train an agent to detect interestingness ? What if we could let designers draw their levels in Paint?
I went to this workshop with a slight apprehension, but I left with admiration and excitement for what our field will produce next.
Wrapping Up
Thanks once again to Victoire for their wonderful write-up. I really appreciate the overview of all the papers published, as well as their perspectives on how the field itself is evolving, particularly in an era of generative AI expansion! Links have been provided to the conference and the workshop above (and right here) for those interested in finding out more. At this time the final proceedings (i.e. the collection of published academic papers) isn’t live yet. However I would expect them to come out in due course! Critically for the PCG workshop papers, the organisation does a great job of maintaining a database of all previously published papers at the venue.
My hope is that we can continue to have these overviews of academic conferences in the future, and there are plenty more coming up this year, including the IEEE Conference on Games in August, and the AAAI’s AI for Interactive Digital Entertainment (AIIDE) in November. Once again a reminder to all of our scholarly readers, if you’re participating in an academic conference and want to help produce these summaries please get in touch!
And with, we’ll bring this edition to a close. Thank you all for your continued support of the newsletter. We’ll be back in a few weeks time once I’ve had some proper downtime, and fingers crossed we’ll have some big stuff to announce when I get back!